PS.本文章基于https://course.rs/advance-practice1/intro.html,内容按照我自己的理解重新编排了一下,希望会有用(
web服务器要做的事
- 监听本地IP的某个端口传入的TCP连接
- 对传入的连接进行处理
在这里,我们的客户端是浏览器,那么TCP连接所带的数据就是HTTP请求了,GET请求报文大概长这样:

我们的玩具服务器所要做的事情很简单,假设我们监听127.0.0.1:7878,根据不同的访问的地址来返回不同的HTTP响应
HTTP的响应报文是这样的:
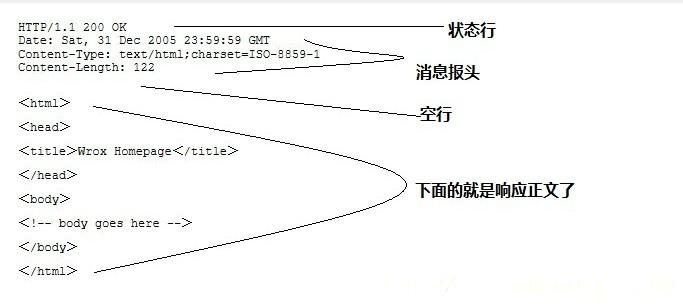
我们甚至只需要设置第一页的状态行和Content-Length(正文长度)就行了,然后响应正文部分就是html代码
如果GET的是根目录(http://127.0.0.1:7878),设置状态行为HTTP/1.1 200 OK表示成功,body部分为简单的html,让浏览器显示出东西
如果GET的是其他地方(比如http://127.0.0.1:7878/abcd),状态行就设置为HTTP/1.1 404 NOT FOUND表示没有这个网页,body部分为另一个表示404的html
我们用2个html,一个是hello.html,用于根目录网址的响应:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>

就是左上角显示这个而已
一个是404.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>404!</title>
</head>
<body>
<h1>Sorry</h1>
<p>404 Not found</p>
</body>
</html>
显示404
单线程版本实现
主体部分是这样的
use std::{
fs,
io::{BufRead, BufReader, Write},
net::{TcpListener, TcpStream},
}; // 先不管这些,编译器会帮你引入的
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").expect("Can not bind");
for stream in listener.incoming() {
let stream = stream.expect("Connection failed");
handle_connection(stream);
}
}
我们使用TcpListener::bind("127.0.0.1:7878")来创建一个TCP socket,因为端口可能会被占用,所以我们expect一下,被占用就崩溃呗
然后我们迭代listener.incoming(),这就相当于while true循环等待连接,只不过用了for的语法
因为有连接传入不一定能成功建立连接,所以得unwrap/expect一下
然后我们就用自己定义的handle_connection来处理连接了
fn handle_connection(mut stream: TcpStream) {
// read stream
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, file_name) = match request_line.as_str() {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let html_content =
fs::read_to_string(file_name).expect("Something went wrong reading the file");
let html_len = html_content.len();
let content = format!("{status_line}\r\nContent-Length: {html_len}\r\n\r\n{html_content}");
stream.write_all(content.as_bytes()).expect("Write failed");
}
Tcp传数据是以字节流的形式的,为了避免频繁读取,我们用一个缓冲区BufReader来存放数据,并用lines()返回以行为单位的String迭代器.这里第一个unwrap()是因为next()返回Option,第二个是io的Result<String>.我们只需要请求的第一行就可以了,所以用了next()而不是for遍历
然后根据request_line的内容去给出不同的响应
我的html是放在代码根目录上了,所以用fs::read_to_string读html就完事了
还要获得html代码的长度,用来设置Content-Length
然后把这些内容拼起来就可以了,要注意\r\n的数量,这是报文格式规定的
最后把content,也就是响应报文写到TCP连接就可以了
多线程版本实现
单线程版本太捞了,只能处理一个连接,我们可以用多线程同时处理多个连接
多线程下服务器要做的跟单线程差不多:
- 监听本地IP的某个端口传入的TCP连接
- 传入的连接分配给新的线程,该线程处理这个连接
最简单的方式是这样的:
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
简单是简单,但它会生成无上限的线程数,可能会导致资源耗尽
我们希望限制创建线程的数量,第三方库会有线程池来使用,但这里我们想自己手动写一个线程池
新建一个文件lib.rs,在这里写,我们创建一个叫ThreadPool的结构
我们想实现这样的功能:
- 初始化
ThreadPool::new(最大线程数)线程池创建好线程 ThreadPool.exec(|| func)线程池把任务(函数)丢给池中的一个线程,该线程执行完之后不销毁,回到池中待命,不然频繁地增删线程开销比较大,这也是线程池的初衷(不然我们用计数器就完事了)
如何把任务丢给线程?也就是我们要把数据发给线程(函数也是数据),我们可以使用消息队列,而且是多生产者单消费者的(多个任务可以同时提交给线程池,但是只允许一个线程拿走其中的一个任务),rust的标准库就有这样的东西std::sync::mpsc
由此可见,我们的线程池应有2个部分:
- 存储线程,使用
Vec就不错 - 消息队列,线程池是生产者,也就是发送者
sender
线程的类型是什么? 根据thread::spawn()的类型签名
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
}
可以得到是JoinHandle<T>,其实就是线程句柄(也可以看作标识符),T是闭包返回的类型,这里我们不用返回,用()即可
那我们直接用Vec<JoinHandle<()>>来存就可以了吗? 其实也可以,但是为了后续管理(比如我们想用一个id来表示线程号),我们新创建一个Worker结构来存:
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
最后,ThreadPool长这样:
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>, //消息队列中发射的那一端
}
type Job = Box<dyn FnOnce() + Send + 'static>; //该类型代表传入的任务(函数)
Job也是根据thread::spawn()的类型签名得到的
然后就是实现了
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender,
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
mpsc::channel()返回两个类型,一个就是Sender,一个是Receiver,分别代表发送/接收端
mpsc中,Sender可以clone,能由多个线程拥有.但Receiver不行,但可以发送引用给其他线程,即使用Arc引用计数.而且还得保证同一个时间只有一个Receiver 能接收消息,否则一个任务可能同时被多个 Worker 执行,所以还要加上Mutex来互斥使用接收端.然后我们把id和接收端给Worker就完成初始化了
execute(func)接收任务,然后立即往队列里发,使用send()就完事了,其中一个Worker收到任务,就去执行
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}
其实这里我不太喜欢这种写法,在new里就执行东西了,不知道有没有更好的做法
总之,new的时候就创建了一个新线程,在里面循环接收信息,获得任务之后就执行该任务
由于recv()是阻塞的,线程不会拼命循环去跑
完
最后
正如原文所说的,本文的实现方法并不是在 Rust 中实现 Web 服务器的最佳方法
一般来说,现代化的 web 服务器往往都基于更加轻量级的协程或 async/await (异步)等模式实现
完整代码可以看 https://course.rs/advance-practice1/graceful-shutdown.html#完整代码
原文最后还做了一点收尾工作,我觉得没有必要,就没讲了(