本项目代码可在 https://github.com/LyntNy4n/simple-groupcache 找到
原版实现
LRU
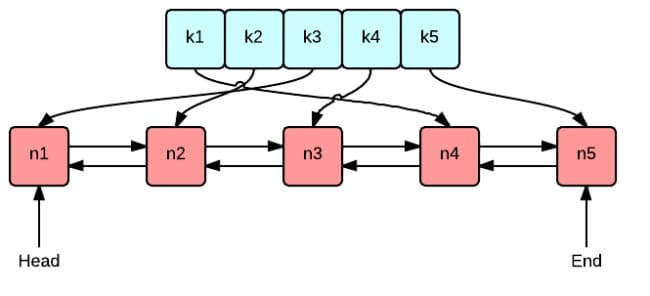
LRU机制需要一个双链表和一个哈希表实现,另外再提供一些属性来辅助
type LRU struct {
maxByte int64 // 允许使用的最大内存
currByte int64 // 当前已使用的内存
list *list.List // 双向链表
hashmap map[string]*list.Element // 键是字符串,值是双向链表中对应节点的指针
callback OnEvicted // 某条记录被移除时的回调函数,可以为 nil
}
// OnEvicted 当key-value被淘汰时 执行的处理函数
type OnEvicted func(key string, value Lengthable)
// Value 定义双向链表节点所存储的对象
type Value struct {
key string
value Lengthable
}
// Lengthable 接口指明对象可以获取自身占有内存空间大小 以字节为单位
type Lengthable interface {
Len() int
}
查找
查找主要有 2 个步骤,第一步是从字典中找到对应的双向链表的节点,第二步,将该节点移动到队尾
删除
实际上是缓存淘汰。即移除最近最少访问的节点(队首)
注意: 如果回调函数不为空,则调用回调函数
新增/修改
- 如果键存在,则更新对应节点的值,并将该节点移到队尾。
- 不存在则是新增场景,首先队尾添加新节点
&entry{key, value}, 并字典中添加 key 和节点的映射关系
还需要更新 currByte,如果超过了设定的最大值 maxByte,则移除最少访问的节点
ByteView
- ByteView 只有一个数据成员,
b []byte,b 将会存储真实的缓存值。选择 byte 类型是为了能够支持任意的数据类型的存储,例如字符串、图片等。 - 实现
Len() int方法,我们在 lru.Cache 的实现中,要求被缓存对象必须实现 Value 接口,即Len() int方法,返回其所占的内存大小。 b是只读的,使用ByteSlice()方法返回一个拷贝,防止缓存值被外部程序修改。
type ByteView struct {
b []byte
}
并发特性
为 lru.Cache 添加并发特性,主要是使用互斥锁Mutex,确保一次只有一个协程(goroutine)可以访问该变量以避免冲突
这样设计可以进行cache和算法的分离,如果之后实现了lfu缓存模块,只需替换cache成员即可(或者用接口)
type mutexCache struct {
mu sync.Mutex
lru *lru.Cache
capacity int64 // 缓存最大容量
}
Group模块
回调函数 Retriever
如果缓存不存在,应从数据源(文件,数据库等)获取数据并添加到缓存中。因此,我们需要设计一个回调函数,在缓存不存在时,调用这个函数,得到源数据。
// Retriever 要求对象实现从数据源获取数据的能力
type Retriever interface {
retrieve(string) ([]byte, error)
}
type RetrieverFunc func(key string) ([]byte, error)
// RetrieverFunc 通过实现retrieve方法,使得任意匿名函数func
// 通过被RetrieverFunc(func)类型强制转换后,实现了 Retriever 接口的能力
func (f RetrieverFunc) retrieve(key string) ([]byte, error) {
return f(key)
}
Group 的定义
Group 提供命名管理缓存/填充缓存的能力
type Group struct {
name string // 命名空间
cache *mutexCache
retriever Retriever
server Picker // 实现了Picker接口的Server
flight *singlefilght.Flight // 防止缓存击穿
}
var (
mu sync.RWMutex // 管理读写groups并发控制
groups = make(map[string]*Group)
)
server和flight会在之后讲解
group的get方法流程:
- 从
cache中查找缓存,如果存在则返回缓存值 - 缓存不存在,则调用
load方法,它会调用getLocally方法(分布式场景下会调用getFromPeer从其他节点获取)getLocally调用用户回调函数g.retriever.retrieve()获取源数据,并且将源数据添加到缓存cache中getFromPeer通过server选择一个合适节点,然后向该节点请求数据,但不添加到缓存中
这个get方法其实就是一个请求,所以会在一开始使用singlefilght的Fly方法防止击穿
singlefilght 防击穿模块
将所有由key产生的请求抽象成flight,这个flight只会起飞一次(single) 这样就可以缓解击穿的可能性
flight载有我们要的缓存数据 称为packet,也可以叫call,因为对应着一次请求
type packet struct {
wg sync.WaitGroup
val interface{}
err error
}
packet要能做这几个事情:
- 能够存值,第一个请求回来的时候,值赋给
val - 要能够同步,第一个请求下去之后,后面的请求发现有同名
key下去了,那么就地等待,这里通过 wg 来同步这个行为。第一个请求回来之后,通过 wg 来唤醒 - 要能够存 error ,如果有错误,那么要能存起来
type Flight struct {
mu sync.Mutex
flight map[string]*packet
}
Flight 结构是用来存储 k-v 的,key 是用户请求 key ,value 是请求,抽象为了 packet 。
最后就是防止击穿的逻辑了:
- 如果
map里面有同名key,那说明已经有人在查了,那么就地等待,等唤醒之后,直接返回值 - 如果
map没有同名key,那说明没人查过,那就是要这个请求亲自去查.我们创建一个packet对象,把请求自己的 key 放进去,这样别人就能感知到他已经去服务端拿数据了
// Fly 负责key航班的飞行 fn是获取packet的方法
func (f *Flight) Fly(key string, fn func() (interface{}, error)) (interface{}, error) {
f.mu.Lock()
// 结构未初始化
if f.flight == nil {
f.flight = make(map[string]*packet)
}
// 航班已起飞(已缓存该key的数据) 则等待
if p, ok := f.flight[key]; ok {
f.mu.Unlock()
p.wg.Wait() // 等待航班完成
return p.val, p.err
}
// 航班未起飞(未缓存该key的数据) 则创建packet
p := new(packet)
p.wg.Add(1)
f.flight[key] = p
f.mu.Unlock()
// 创建packet后,航班起飞(获取数据)
p.val, p.err = fn()
p.wg.Done() // 航班完成
f.mu.Lock()
delete(f.flight, key)
f.mu.Unlock()
return p.val, p.err
}
⼀致性哈希模块
使用一个结构来维护算法
// HashFunc 定义哈希函数输入输出
type HashFunc func(data []byte) uint32
// Consistency 维护peer与其hash值的关联
type Consistency struct {
hash HashFunc // 哈希函数依赖
replicas int // 虚拟节点个数(防止数据倾斜)
ring []int // uint32哈希环
hashmap map[int]string // hashValue -> peerName
}
hash可以使用自定义的 Hash 函数,也方便测试时替换,默认为 crc32.ChecksumIEEE 算法
添加节点
// Register 将各个peer注册到哈希环上
func (c *Consistency) Register(peersName ...string) {
for _, peerName := range peersName {
for i := 0; i < c.replicas; i++ {
hashValue := int(c.hash([]byte(strconv.Itoa(i)+peerName)))
c.ring = append(c.ring, hashValue)
c.hashmap[hashValue] = peerName
}
}
sort.Ints(c.ring)
}
对每一个真实节点 key,对应创建 m.replicas 个虚拟节点,虚拟节点的名称是strconv.Itoa(i) + key,即通过添加编号的方式区分不同虚拟节点
比如有3个节点p1,p2,p3,replicas设为3,那么p1在哈希环上将有3个对应节点:1p1,2p1,3p1
计算key归哪个节点
// GetPeer 计算key应缓存到的peer
func (c *Consistency) GetPeer(key string) string {
if len(c.ring) == 0 {
return ""
}
hashValue := int(c.hash([]byte(key)))
// 二分查找, 找到第一个大于等于(等效于顺时针)hashValue的hash值
idx := sort.Search(len(c.ring), func(i int) bool {
return c.ring[i] >= hashValue
})
// 第一个大于等于的hash值的索引可能超出环的长度, 需要取模
return c.hashmap[c.ring[idx%len(c.ring)]]
}
节点选择
有了一致性哈希算法,我们就可以把数据分到不同的节点上了.自然节点自身就需要有获取其他节点的能力
// Picker 定义了获取分布式节点的能力
type Picker interface {
PickPeer(key string) (Fetcher, bool)
}
// Fetcher 定义了从远端获取缓存的能力
// 所以每个Peer应实现这个接口
type Fetcher interface {
Fetch(group string, key string) ([]byte, error)
}
PickPeer() 方法用于根据传入的 key 选择相应节点, 因为所有节点都实现了Fetcher,所以就可以从远端获取缓存了
一般来说,服务端需要定义PickPeer,客户端需要定义Fetch. 而他们的实现会因采用通信方式的不同而不同,所以这个接口会在客户端/服务端的地方实现
服务端/客户端设计
分布式缓存需要实现节点间通信,如果一个节点启动了服务端,那么这个节点就可以被其他节点访问
建立基于 HTTP 的通信机制是比较常见和简单的做法,但是也可以使用GRPC通信
无论采用什么通信机制,服务端一般需要提供以下方法:
NewServer,创建服务器Start,初始化socket并开始监听,注册各种服务,启动服务器Stop,停止服务器,清理资源Get,输入参数:group string,key string,因为有不同的group,该方法就是负责找到对应的group,然后调用group.Get(key),返回响应(ByteView)SetPeers,将各个远端主机IP配置到Server里,这样Server才可以选择到它们PickPeer,就是节点选择,根据一致性哈希选举出key应存放在的Fetcher(节点)
注册各种服务环节要做的事情挺多:
-
如果使用HTTP通信,就要注册不同url的handle
-
如果使用GRPC通信,就要把rpc服务注册到grpc中,这样grpc收到request可以分发给server处理
-
分布式服务注册/发现:需要使用一种机制,让节点知道彼此的存在,可以访问到其他节点
这种机制要么自己实现(哈希表+锁),要么使用现成的,比如
etcd
客户端一般需要提供以下方法:
NewClient,新建客户端Fetch,从远端节点获取缓存.该方法需要依靠发现服务,获取远端节点的连接,这样才可以往该连接调用方法,获取响应
GRPC
因为我们使用etcd,它就是依靠grpc通信的,那我们就使用grpc,而且如果使用grpc网关,我们还可以获得http通信的功能
定义groupcache.proto文件,放在了proto目录
syntax = "proto3";
package pb;
option go_package = "simple-groupcache/pb";
message GetRequest {
string group = 1;
string key = 2;
}
message GetResponse {
bytes value = 1;
}
service Groupcache {
rpc Get(GetRequest) returns (GetResponse);
}
使用protoc生成对应代码:
protoc --proto_path=proto --go_out=pb --go_opt=paths=source_relative \
--go-grpc_out=pb --go-grpc_opt=paths=source_relative \
proto/*.proto
服务端
//全局设定
const (
defaultAddr = "127.0.0.1:6324"
defaultReplicas = 50
)
var (
defaultEtcdConfig = clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
}
)
// server 和 Group 是解耦合的 所以server要自己实现并发控制
type server struct {
pb.UnimplementedGroupcacheServer
addr string // format: ip:port
status bool // true: running false: stop
stopSignal chan error // 通知registry revoke服务
mu sync.Mutex
consHash *consistenthash.Consistency // 一致性哈希
clients map[string]*client // 保存各个远端主机的client
}
比较重要的是addr,mu,consHash,clients,其他是配合etcd服务使用的
代码中提到server 和 Group 是解耦合的,你可以这样理解: group是一个有着名字的缓存空间,如果没有分布式,group是完全可以去掉server的.如果需要分布式,那group就需要有与其他group通信的能力,这个能力就是server给予的,所以使用的时候,还需要调用RegisterSvr
// RegisterSvr 为 Group 注册 Server
func (g *Group) RegisterSvr(p Picker) {
if g.server != nil {
panic("group had been registered server")
}
g.server = p
}
新建
// NewServer 创建cache的svr 若addr为空 则使用defaultAddr
func NewServer(addr string) (*server, error) {
if addr == "" {
addr = defaultAddr
}
if !validPeerAddr(addr) {
return nil, fmt.Errorf("invalid addr %s, it should be x.x.x.x:port", addr)
}
return &server{addr: addr}, nil
}
这个方法只是设置了addr,其他都是默认值
启动
// Start 启动cache服务
func (s *server) Start() error {
s.mu.Lock()
if s.status {
s.mu.Unlock()
return fmt.Errorf("server already started")
}
// 1. 设置status为true 表示服务器已在运行
s.status = true
// 2. 初始化stop channal,这用于通知registry停止keepalive
s.stopSignal = make(chan error)
port := strings.Split(s.addr, ":")[1]
// 3. 初始化tcp socket并开始监听
lis, err := net.Listen("tcp", ":"+port)
if err != nil {
return fmt.Errorf("failed to listen: %v", err)
}
// 4. 启动grpc服务,注册rpc服务至grpc 这样grpc收到request可以分发给server处理
grpcServer := grpc.NewServer()
pb.RegisterGroupcacheServer(grpcServer, s)
// 注册服务/撤销服务
go func() {
// 5. 将自己的服务名/Host地址注册至etcd 这样client可以通过etcd找到其他节点
// Register服务会一直阻塞 阻塞即意味着在此期间节点注册成功,可以被发现
err := registry.Register("cache", s.addr, s.stopSignal)
if err != nil {
log.Fatalf(err.Error())
}
// 撤销服务 关闭channel和tcp socket
close(s.stopSignal)
err = lis.Close()
if err != nil {
log.Fatalf(err.Error())
}
log.Printf("[%s] Revoke service and close tcp socket ok.", s.addr)
}()
s.mu.Unlock()
// 6. 启动grpc服务
if err := grpcServer.Serve(lis); s.status && err != nil {
return fmt.Errorf("failed to serve: %v", err)
}
return nil
}
registry.Register()方法有关etcd,但是有个通用模板,照着写就可以的
设定远端节点
// SetPeers 将各个远端主机IP配置到Server里
// 这样Server就可以Pick他们了
// 注意: 此操作是*覆写*操作!
// 注意: peersIP必须满足 x.x.x.x:port的格式
func (s *server) SetPeers(peersAddr ...string) {
s.mu.Lock()
defer s.mu.Unlock()
// 初始化一致性哈希并注册各个节点
s.consHash = consistenthash.New(defaultReplicas, nil)
s.consHash.Register(peersAddr...)
// 初始化各个节点的client
s.clients = make(map[string]*client)
for _, peerAddr := range peersAddr {
if !validPeerAddr(peerAddr) {
panic(fmt.Sprintf("[peer %s] invalid address format, it should be x.x.x.x:port", peerAddr))
}
service := fmt.Sprintf("cache/%s", peerAddr)
s.clients[peerAddr] = NewClient(service)
}
}
根据key选择节点
// PickPeer 根据一致性哈希选举出key应存放在的节点
// return nil,false 代表从本地获取cache
func (s *server) PickPeer(key string) (Fetcher, bool) {
s.mu.Lock()
defer s.mu.Unlock()
peerAddr := s.consHash.GetPeer(key)
// Pick itself
if peerAddr == s.addr {
log.Printf("ooh! pick myself, I am %s\n", s.addr)
return nil, false
}
log.Printf("[cache %s] pick remote peer: %s\n", s.addr, peerAddr)
return s.clients[peerAddr], true
}
// 测试Server是否实现了Picker接口
var _ Picker = (*server)(nil)
停止
// Stop 停止server运行 如果server没有运行 这将是一个no-op
func (s *server) Stop() {
s.mu.Lock()
if !s.status {
s.mu.Unlock()
return
}
s.stopSignal <- nil // 发送停止keepalive信号
s.status = false // 设置server运行状态为stop
s.clients = nil // 清空一致性哈希信息 有助于垃圾回收
s.consHash = nil
s.mu.Unlock()
}
客户端
客户端比服务端简单得多
type client struct {
name string // 服务名称 pcache/ip:addr
}
func NewClient(service string) *client {
return &client{name: service}
}
获取节点缓存
// Fetch 从remote peer获取对应缓存值
func (c *client) Fetch(group string, key string) ([]byte, error) {
// 创建一个etcd client
cli, err := clientv3.New(defaultEtcdConfig)
if err != nil {
return nil, err
}
defer cli.Close()
// 发现服务 取得与服务的连接
conn, err := registry.EtcdDial(cli, c.name)
if err != nil {
return nil, err
}
defer conn.Close()
// 创建grpc client
grpcClient := pb.NewGroupcacheClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
// 发送请求
resp, err := grpcClient.Get(ctx, &pb.GetRequest{
Group: group,
Key: key,
})
if err != nil {
return nil, fmt.Errorf("could not get %s/%s from peer %s", group, key, c.name)
}
return resp.GetValue(), nil
}
// 测试Client是否实现了Fetcher接口
var _ Fetcher = (*client)(nil)
registry.EtcdDial同样和ectd有关,这里不详细说,一时半会也说不明白
新增功能
缓存淘汰策略
除了LRU,还有其他常用的策略:
- FIFO:先进先出就是每次淘汰最早添加的记录,但是很多记录添加地早也访问的很频繁,因此命中率不⾼
- LFU:淘汰缓存中使⽤频率最低的,LFU认为如果数据过去被访问多次,那么将来被访问的频率也会更⾼。LFU的实现需要维护⼀个按照访问次数排序的队列,每次访问后元素的访问次数改变,队列重新排序。
- ARC:ARC 介于 LRU 和 LFU 之间,借助 LRU 和 LFU 基本思想实现,以获得可⽤缓存的最佳使⽤
我们不妨尝试添加LFU和ARC策略
首先我们需要一个接口,这样可以在mutexCache中方便切换策略
新建文件simple-groupcache/cache-strategy/icache.go,把原版LRU中的一些代码剪切过来
package cachestrategy
// Lengthable 接口指明对象可以获取自身占有内存空间大小 以字节为单位
type Lengthable interface {
Len() int
}
// OnEvicted 当key-value被淘汰时 执行的处理函数
type OnEvicted func(key string, value Lengthable)
type CacheStrategy interface {
Get(key string) (value Lengthable, ok bool)
Add(key string, value Lengthable)
}
LRU修改
然后为了后面的ARC实现,需要修改和添加一些方法,另外currByte等字段改成公共的
type Cache struct {
MaxByte int64 // Cache 最大容量(Byte)
CurrByte int64 // Cache 当前容量(Byte)
hashmap map[string]*list.Element
doublyLinkedList *list.List // 链头表示最近使用
callback cachestrategy.OnEvicted // 淘汰回调
}
// 确保Cache实现了CacheStrategy接口
var _ cachestrategy.CacheStrategy = (*Cache)(nil)
//添加Contains 看看key存不存在(不访问)
func (c *Cache) Contains(key string) bool {
if _, ok := c.hashmap[key]; ok {
return true
}
return false
}
//添加Remove 删除特定key的数据
func (c *Cache) Remove(key string) {
if elem, ok := c.hashmap[key]; ok {
entry := elem.Value.(*Node)
delete(c.hashmap, key)
c.doublyLinkedList.Remove(elem)
c.CurrByte -= int64(len(key)) + int64(entry.value.Len())
}
}
// 修改Evict 返回淘汰后的kv
func (c *Cache) Evict() (string, cachestrategy.Lengthable) {
tailElem := c.doublyLinkedList.Back()
if tailElem != nil {
entry := tailElem.Value.(*Node)
k, v := entry.key, entry.value
delete(c.hashmap, k) // 移除映射
c.doublyLinkedList.Remove(tailElem) // 移除缓存
c.CurrByte -= int64(len(k)) + int64(v.Len()) // 更新占用内存情况
// 移除后的善后处理
if c.callback != nil {
c.callback(k, v)
}
return k, v
}
return "", nil
}
LFU
实现细节不多说,可以去网上搜,或者看github上的代码
ARC
ARC是一种平衡访问时间优先和访问频率优先的策略,而且LRU和LFU都会用到,更复杂,详情不解释了
修改其他地方
mutexCache模块中newCache需要修改,在这里选择好淘汰策略,也就不延迟初始化了
func newCache(capacity int64, cacheStrategy string) *mutexCache {
var cache cachestrategy.CacheStrategy
switch cacheStrategy {
case "lru":
cache = lru.New(capacity, nil)
case "lfu":
cache = lfu.New(capacity, nil)
case "arc":
cache = arc.New(capacity, nil)
default:
cache = lru.New(capacity, nil)
}
return &mutexCache{
cache: cache,
capacity: capacity,
}
}
然后其他文件跟newCache有关的也要加上cacheStrategy这个参数,这个修改就简单了,不多说
参考链接
Geecache 7天用Go从零实现分布式缓存GeeCache教程
peanutcache 基于Geecache和groupcache的改版,加入了grpc和etcd等内容,非常详细的注释
gcache 基于Geecache的改版,加入了更多的缓存淘汰策略