本项目simple groupcache是groupcache的改版实现,为了简单起见,简化了一些模块的同时又增加了一些功能
我们先实现简化后原版的功能,然后再去增加功能
groupcache 简介
groupcache 是一个基于Golang的小巧的 kv 存储库,最大的特点是没有设置/更新/删除内容的接口,带来的好处就是没有覆盖更新带来的一致性问题,但正因如此,这个库是有自己的特殊场景的,需要业务自己满足这种场景的使用(不频繁的更新,比如缓存一些静态文件,用文件 md5 作为 key,value 就是文件)
groupcache 没有更新和删除接口,那么空间岂不是会越来越多?
groupcache 没有 set,update,delete 接口只是让用户无法更新和删除已经缓存的内容而已,而不是说设置进去的 kv 要永久保存,缓存空间肯定不是无限的,groupcache 内部是通过 LRU 来管理内容
groupcache 没有 set 接口,那内容是怎么设置进去?
- 初始化的时候,就需要明确当 key miss 的时候,怎么获取到内容的手段,把这个手段配置好是前提
- get 调用的时候,当 key miss 的时候,就会调用初始化的获取手段来获取数据,如果 hit 的话,那么就直接返回
架构设计
主要分为了 Group 模块,缓存模块,分布式⼀致性等模块
Group模块
groupcache 封装 Group 这个对象来对外提供服务,Group提供命名管理缓存/填充缓存的能力
这个结构提供的函数就是对外使用的 API, 但没有更改/删除的接口
client & server
groupcache 实现的库是 client 也是 server,即groupcache 实现的是一个分布式的无中心化的缓存集群。每个节点,既作为 server ,对外提供 api 访问,返回 key 的数据,也能作为客户端访问其他节点(去问其他节点有没有缓存数据)
缓存模块
缓存模块是数据实际存储的位置,其中实现缓存淘汰算法,过期机制,回调机制等,缓存模块与其他部分是解耦的,因此可以根据不同场景选择不同的缓存淘汰算法(默认lru)。
groupcache本身的实现中,缓存值只淘汰不更新,也没有超时淘汰机制,通过这样来简化设计,并没有指定缓存的移除操作。
ByteView 模块
如果获取缓存值时直接返回缓存值的切⽚,那个切⽚只是原切⽚浅拷⻉,真正的缓存值就可能被外部恶意修改。所以⽤byteview进⾏⼀层封装,返回缓存值原切⽚的深拷⻉
⼀致性哈希模块
实现⼀致性哈希算法是从单节点走向分布式节点的一个重要的环节,其将机器节点组成哈希环,为每个节点提供了从其他节点获取缓存的能⼒
一致性哈希算法: 在新增/删除节点时,只需要重新定位该节点附近的一小部分数据,而不需要重新定位所有的节点
算法将 key 映射到 232 的空间中,将这个数字首尾相连,形成一个环
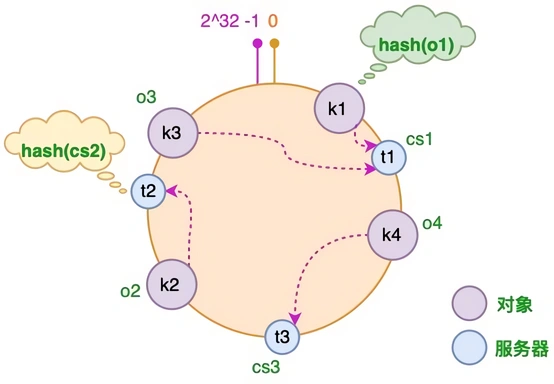
将对象和服务器都放置到同一个哈希环后,在哈希环上顺时针查找距离这个对象的 hash 值最近的机器,即是这个对象所属的机器
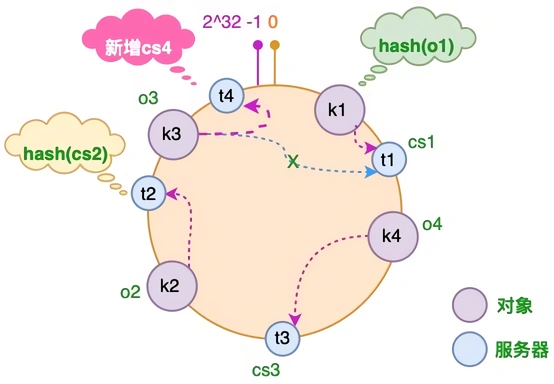
增加一台服务器 cs4的情况下,只有 o3 对象需要重新分配
如果使用简单的取模方法,当新添加服务器时可能会导致大部分缓存失效
防击穿模块
一个 k-v 存储,客户端先看是否有 k 的缓存,如果有,那么直接给用户返回,如果没有,则向后端存储请求。
如果突然来了1万个这样的请求,发现都是 miss,那么都去后端拉数据了,这种就可能会一下导致后端压力暴涨。其实,这种场景,只要第一个人发下去了就行了,其他的请求等着这个请求返回就好了,大家都是请求同一个值。
内部实现了 singlefilght 就是解决这个问题的
协商填充(本项目不实现)
固定的 key 由固定的节点服务,这个相当于一个绑定。举个例子,A,B,C 三个节点,如果请求发给了 A,节点 A 哈希计算发现这个请求应该是 B 节点执行,那么会转给 B 执行。这样只需要 B 节点把这个请求处理好即可,这样能防止在缓存 miss 的时候,整个系统节点的惊群效应。
通过这种协商才能保证请求聚合发到 B,同一时间 B 收到大量相同 key 的请求,无论自己有没有,都能很好处理,因为有之前说的防击穿的措施:
- 如果 B 有,立马返回就行;
- 如果没有也只是放一个请求下去,后端压力可以很小的;
预热机制(本项目不实现)
这个其实是和协商填充一起达到的效果,请求实现了节点绑定,那么在分布式集群的模式下,很容易实现预热的效果,你这个请求大概率是已经被其他节点缓存了的。
热点数据多节点备份(本项目不实现)
分布式缓存系统中,一般需要从两个层面考虑热点均衡的问题:
- 大量的 key 是否均衡的分布到节点;这个指请求数量的分布均衡
- 某些 key 的访问频率也是有热点的,也是不均衡的;
针对第一点,不同节点会负责特定的 key 集合的查询请求,一般来讲只要哈希算法还行, key 的分布是均衡的,但是针对第二点,如果某些 key 属于热点数据而被大量访问,这很会导致压力全都在某个节点上。
groupcache 有一个热点数据自动扩展机制用来解决这个问题,针对每个节点,除了会缓存本节点存在且大量访问的 key 之外,也会缓存那些不属于节点的(但是被频繁访问)的 key,缓存这些 key 的对象被称为 hotcache。
协商机制和多节点备份这两个特性是 groupcache 的杀手级特性。
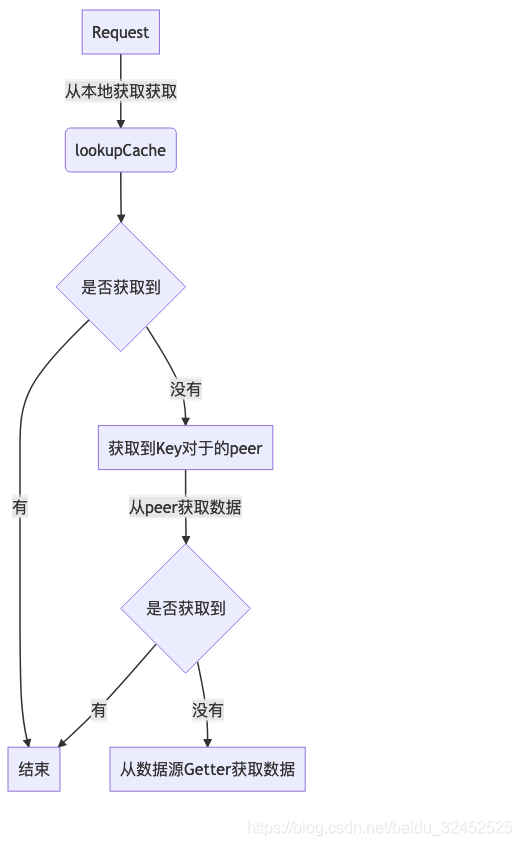
大致流程
- 当 Group 模块接收到请求时,当前节点先到本地的主缓存中查找是否有⽬标值。
- 如果没有再查看此节点的热点缓存中是否有,如果也没有,就需要到远程伙伴节点去获取
- 通过⼀致性哈希计算该 key 的哈希值,找到哈希环上相应的节点,执⾏该节点的远程调⽤函数获取值,并把该值加⼊到当前节点的热点缓存中
- 如果该key在哈希环中对应的就是当前节点,那么就需要从本地的数据源去获取数据后加载到当前节点的主缓存中