本文基于 https://picklenerd.github.io/pngme_book/introduction.html 精简了一下并附带了自己的理解
我们要制作一个命令行程序PNGme,可以在 PNG 文件中隐藏秘密消息
完整代码可见 https://github.com/LyntNy4n/pngme
需要做什么?
程序将有四个命令:
- Encode a message into a PNG file
将消息编码为 PNG 文件 - Decode a message stored in a PNG file
解码存储在 PNG 文件中的消息 - Remove a message from a PNG file
从 PNG 文件中删除消息 - Print a list of PNG chunks that can be searched for messages
打印可搜索消息的 PNG 块列表
初始配置
使用 cargo new --bin pngme 创建一个新的二进制项目,将将以下代码复制到 main.rs 文件中
mod args;
mod chunk;
mod chunk_type;
mod commands;
mod png;
pub type Error = Box<dyn std::error::Error>;
pub type Result<T> = std::result::Result<T, Error>;
fn main() -> Result<()> {
todo!()
}
接下来我们就要完成各个模块,先把各模块的rs文件在src目录中创建好,以免报错
在上面代码中提供了 Error 和 Result 类型别名,它们可以让你在代码中轻松使用 ? 运算符,也可以用第三方库anyhow做到同样的
PNG 文件结构规范 需要去看一下,下面也会有讲到
PS. 原文还提供了每个模块的测试用例,但是太长了,这里就不列出来了.可以去原文章去看,或者github上的完整代码里也有
Chunk Types 块类型
PNG 文件本质上只是一个“块”列表,每个块都包含自己的数据。每个块都有一个可以表示为 4 个字符的字符串的类型。像图像数据这样的东西有标准的块类型,但是没有规则会阻止你插入你自己的块和你想要的任何数据。我们甚至可以告诉 PNG 解码器忽略我们的块
Chunk Type的通俗解释
一个块类型就是4个以字节表示的ASCII码英文字母,比如BLOB,RUST,Wuhu
不过还是有一些规则的,这些规则代表了不同的含义:
每个字节的第5位(从0开始,对应二进制值的32)用于传达块属性。者意味着人们可以根据类型代码的每个字母是大写(第 5 位为 0)还是小写(第 5 位为 1)来读取分配的属性,不同字节的第5位有不同的含义
- 辅助位:第一个字节的第 5 位
0 (uppercase) = critical, 1 (lowercase) = ancillary
0(大写)= 关键,1(小写)= 辅助
遇到辅助位为 1 的未知块的解码器可以安全地忽略该块并继续显示图像,比如时间块 (tIME)
- 私有位:第二个字节的第 5 位
0 (uppercase) = public, 1 (lowercase) = private
0(大写)= 公共,1(小写)= 私有
公共块是 PNG 规范的一部分或在 PNG 专用公共块类型列表中注册的块。应用程序还可以为自己的目的定义私有(未注册)块
- 保留(Reserved)位:第三个字节的第5位
第三个字母大小写的意义是为将来可能的扩展保留的。目前所有的块名都必须有大写(0)的第三个字母
- 安全复制位: 第四个字节的第5位
0 (uppercase) = unsafe to copy, 1 (lowercase) = safe to copy
0(大写)= 复制不安全,1(小写)= 复制安全
如果块的安全复制位为 1,则无论软件是否识别块类型,也不管文件修改的范围如何,都可以将块复制到修改后的 PNG 文件
如果块的安全复制位为 0,则表示该块依赖于图像数据。如果程序对关键块进行了任何更改,包括关键块的添加、修改、删除或重新排序,则不得将无法识别的不安全块复制到输出 PNG 文件中
实现块类型
在chunk_type.rs中开写
我们要在Rust中复刻PNG的块类型,需要提供以字节为单位返回块类型的方法,检查整个块类型的有效性,并检查四个字节中每个字节的大写特殊含义。下面提供了方法签名
fn bytes(&self) -> [u8; 4]
fn is_valid(&self) -> bool
fn is_critical(&self) -> bool
fn is_public(&self) -> bool
fn is_reserved_bit_valid(&self) -> bool
fn is_safe_to_copy(&self) -> bool
// 还要实现 TryFrom<[u8; 4]>, FromStr, Display, PartialEq 和 Eq
也许最简单的ChunkType就是这样:
pub struct ChunkType {
bytes: [u8; 4],
}
//或者这样也可以
pub struct ChunkType {
first_byte: u8,
second_byte: u8,
third_byte: u8,
fourth_byte: u8,
}
在这里,我们玩花的,使用第二种表示,因为每个字节都有不同的含义,分开表示也不错
然后下面就是各种方法的实现了:
impl ChunkType {
pub fn bytes(&self) -> [u8; 4] {
[
self.first_byte,
self.second_byte,
self.third_byte,
self.fourth_byte,
]
}
pub fn is_critical(&self) -> bool {
self.first_byte & 0b0010_0000 == 0
}
pub fn is_public(&self) -> bool {
self.second_byte & 0b0010_0000 == 0
}
pub fn is_reserved_bit_valid(&self) -> bool {
self.third_byte & 0b0010_0000 == 0
}
pub fn is_safe_to_copy(&self) -> bool {
self.fourth_byte & 0b0010_0000 != 0
}
pub fn is_valid(&self) -> bool {
self.is_reserved_bit_valid()
}
}
fn is_all_alphabetic(bytes: [u8; 4]) -> bool {
bytes.iter().all(|byte| byte.is_ascii_alphabetic())
}
也可以用is_ascii_uppercase(),但按位与应该更快一点,不过这样我们就要保证这4个字节都是ASCII字母了
多写了is_all_alphabetic,用于后续验证
PartialEq, Eq我们derive就可以了,接下来我们实现TryFrom
impl TryFrom<[u8; 4]> for ChunkType {
type Error = &'static str;
fn try_from(bytes: [u8; 4]) -> std::result::Result<Self, Self::Error> {
if !is_all_alphabetic(bytes) {
return Err("ChunkType must be alphabetic");
}
let chunk_type = ChunkType {
first_byte: bytes[0],
second_byte: bytes[1],
third_byte: bytes[2],
fourth_byte: bytes[3],
};
Ok(chunk_type)
}
}
朴实无华,注意这里不用检查第三位是不是小写
然后是FromStr
impl FromStr for ChunkType {
type Err = &'static str;
fn from_str(s: &str) -> Result<Self, Self::Err> {
if s.len() != 4 {
return Err("ChunkType string must be 4 characters long");
}
let mut bytes = [0; 4];
for (i, byte) in s.bytes().enumerate() {
bytes[i] = byte;
}
ChunkType::try_from(bytes)
}
}
用tryfrom,爽死辣(
Display显示字母就好了
impl Display for ChunkType {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
let bytes = self.bytes();
for byte in bytes.iter() {
write!(f, "{}", *byte as char)?;
}
Ok(())
}
}
Chunk 块
我们已经有了 ChunkType 结构,我们可以实现其余的块了。再次查看 PNG 文件结构规范。 3.2 部分包含需要的所有信息
块布局
每个块由四个部分组成:
Length: 一个 4 字节无符号整数,表示块数据字段中的字节数。长度仅计算数据字段,而不计算其本身、块类型代码或 CRC。零是有效长度。尽管编码器和解码器应将长度视为无符号,但其值不得超过 231 字节
Chunk Type: 一个 4 字节的块类型代码。为了便于描述和检查 PNG 文件,类型代码仅限于由大写和小写 ASCII 字母(A-Z 和 a-z,或 65-90 和 97-122)组成。但是,编码器和解码器必须将代码视为固定的二进制值,而不是字符串(也就是要看作一个一个字节)
Chunk Data: 适合块类型的数据字节。该字段可以是零长度
CRC: 一个4字节的CRC(Cyclic Redundancy Check)是根据chunk前面的字节计算出来的,包括chunk type和chunk data字段,但不包括length字段。 CRC 始终存在,即使对于不包含数据的块也是如此
关于计算 CRC
不头铁,选择第三方库,toml里加入crc = "3.0.1" https://crates.io/crates/crc
我们要实现 PNG 块。这个块应包含上面列出的四段数据,还需要提供方法来返回这四个数据中的每一个,如果块数据是有效的 UTF-8(否则为错误),则块数据被解释为字符串,并且整个块作为字节序列
在chunk.rs中开写
fn new(chunk_type: ChunkType, data: Vec<u8>) -> Chunk
fn length(&self) -> u32
fn chunk_type(&self) -> &ChunkType
fn data(&self) -> &[u8]
fn crc(&self) -> u32
fn data_as_string(&self) -> Result<String>
fn as_bytes(&self) -> Vec<u8>
//还要 TryFrom<&[u8]>, Display
Chunk也分四部分好了:
use crate::chunk_type::ChunkType;
pub struct Chunk {
length: u32,
chunk_type: ChunkType,
data: Vec<u8>,
crc: u32,
}
然后是实现,这里用了万能Result,不然错误类型麻烦
crc的用法够清奇的,得翻文档才知道怎么用
use crate::Result;
impl Chunk {
pub fn new(chunk_type: ChunkType, data: Vec<u8>) -> Chunk {
let length = data.len() as u32;
let crc_content = chunk_type
.bytes()
.iter()
.chain(data.iter())
.copied()
.collect::<Vec<u8>>();
let crc = crc::Crc::<u32>::new(&crc::CRC_32_ISO_HDLC).checksum(&crc_content);
Chunk {
length,
chunk_type,
data,
crc,
}
}
pub fn length(&self) -> u32 {
self.length
}
pub fn chunk_type(&self) -> &ChunkType {
&self.chunk_type
}
pub fn data(&self) -> &[u8] {
&self.data
}
pub fn crc(&self) -> u32 {
self.crc
}
pub fn data_as_string(&self) -> Result<String> {
let string = String::from_utf8(self.data.clone())?;
Ok(string)
}
pub fn as_bytes(&self) -> Vec<u8> {
let mut bytes = Vec::new();
bytes.extend(&self.length.to_be_bytes());
bytes.extend(&self.chunk_type.bytes());
bytes.extend(&self.data);
bytes.extend(&self.crc.to_be_bytes());
bytes
}
}
然后是TryFrom<&[u8]>, Display
impl TryFrom<&[u8]> for Chunk {
type Error = &'static str;
fn try_from(bytes: &[u8]) -> std::result::Result<Self, Self::Error> {
if bytes.len() < 12 {
return Err("Chunk data is too short");
}
let chunk_type_bytes: [u8; 4] = bytes[4..8].try_into().unwrap();
let chunk_type = ChunkType::try_from(chunk_type_bytes)?;
let data = bytes[8..bytes.len() - 4].to_vec();
let crc_bytes: [u8; 4] = bytes[bytes.len() - 4..].try_into().unwrap();
let crc = u32::from_be_bytes(crc_bytes);
let chunk = Chunk::new(chunk_type, data);
if chunk.crc != crc {
return Err("CRC does not match");
}
Ok(chunk)
}
}
impl Display for Chunk {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
let chunk_string = self
.data_as_string()
.unwrap_or_else(|_| String::from("Invalid UTF-8"));
write!(
f,
"Chunk\n\tLength: {}\n\tType: {}\n\tData: {}\n\tCRC: {}",
self.length, self.chunk_type, chunk_string, self.crc
)
}
}
chunk_type_bytes要显式声明成[u8;4]才能转
from_be_bytes将[u8;4]按照大端字节序转成u32
PNG文件
终于到了实现完整PNG文件的时候了,我们还要再看一下PNG文件规范
PNG文件结构
一个 PNG 文件由一个 PNG 签名和后面的一系列块组成
PNG 签名:即文件的前八个字节始终包含以下(十进制)值:
137 80 78 71 13 10 26 10
此签名表明文件的其余部分包含单个 PNG 图像,由一系列以 IHDR 块开始并以 IEND 块结束的块组成
所谓后面的一系列块,就是我们上一节的Chunk
我们需要提供一个构造函数,该构造函数采用块列表、附加和删除块的方法以及返回标头的方法、所有块的一部分以及整个 PNG 文件作为 Vec<u8> 字节
还要求再impl 块中,添加一个名为 STANDARD_HEADER 的公共常量,它具有8 个标准标头字节
在png.rs中开写
fn from_chunks(chunks: Vec<Chunk>) -> Png
fn append_chunk(&mut self, chunk: Chunk)
fn remove_chunk(&mut self, chunk_type: &str) -> Result<Chunk>
fn header(&self) -> &[u8; 8]
fn chunks(&self) -> &[Chunk]
fn chunk_by_type(&self, chunk_type: &str) -> Option<&Chunk>
fn as_bytes(&self) -> Vec<u8>
//还有 TryFrom<&[u8]>, Display
Png结构很容易写出来:
use crate::chunk::Chunk;
use crate::Result; // 后面要用到
pub struct Png {
header: [u8; 8],
chunks: Vec<Chunk>,
}
然后是实现:
impl Png {
const STANDARD_HEADER: [u8; 8] = [137, 80, 78, 71, 13, 10, 26, 10];
pub fn from_chunks(chunks: Vec<Chunk>) -> Png {
Png {
header: Png::STANDARD_HEADER,
chunks,
}
}
pub fn append_chunk(&mut self, chunk: Chunk) {
self.chunks.push(chunk);
}
pub fn remove_chunk(&mut self, chunk_type: &str) -> Result<Chunk> {
let index = self
.chunks
.iter()
.position(|chunk| format!("{}", chunk.chunk_type()) == chunk_type)
.ok_or("Chunk not found")?;
Ok(self.chunks.remove(index))
}
pub fn header(&self) -> &[u8; 8] {
&self.header
}
pub fn chunks(&self) -> &[Chunk] {
&self.chunks
}
pub fn chunk_by_type(&self, chunk_type: &str) -> Option<&Chunk> {
self.chunks
.iter()
.find(|chunk| format!("{}", chunk.chunk_type()) == chunk_type)
}
pub fn as_bytes(&self) -> Vec<u8> {
let mut bytes = Vec::new();
bytes.extend(&self.header);
bytes.extend(
self.chunks
.iter()
.flat_map(|chunk| chunk.as_bytes())
.collect::<Vec<u8>>(),
);
bytes
}
}
可以看到remove_chunk中,我们没有实现Chunk转String/str的方法,但是实现了Display,而Display所做的就是显示字节对应的英文字母,所以直接用format!就可以了
然后是TryFrom, Display
impl TryFrom<&[u8]> for Png {
type Error = &'static str;
fn try_from(bytes: &[u8]) -> std::result::Result<Self, Self::Error> {
if bytes.len() < 8 {
return Err("PNG data is too short");
}
let header: [u8; 8] = bytes[0..8].try_into().unwrap();
if header != Png::STANDARD_HEADER {
return Err("PNG header is invalid");
}
let mut chunks = Vec::new();
let mut index = 8;
while index < bytes.len() {
let length_bytes: [u8; 4] = bytes[index..index + 4].try_into().unwrap();
let length = u32::from_be_bytes(length_bytes) as usize;
let chunk_end = index + 4 + 4 + length + 4; // index + length + type + data + crc
if chunk_end > bytes.len() {
return Err("PNG chunk is too long");
}
let chunk_bytes = &bytes[index..chunk_end];
let chunk = Chunk::try_from(chunk_bytes)?;
chunks.push(chunk);
index = chunk_end;
}
Ok(Png { header, chunks })
}
}
impl Display for Png {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
writeln!(f, "PNG:")?;
for chunk in &self.chunks {
writeln!(f, "{}", chunk)?;
}
Ok(())
}
}
实现CLI
最麻烦的部分以及完成了,现在要做的只是解析用户请求了,也就是设置命令行参数。设置参数将使处理该项目的最后一部分变得非常容易
可以手动解析命令行参数,但用第三方crate是最方便的,clap是不二之选,toml添加clap = { version = "4.2.5", features = ["derive"] } (原文用的是3.0.1,我这里改用最新的,且需要derive特性)
我们需要做到能够使用类似于以下的命令运行程序
pngme encode ./dice.png ruSt "This is a secret message!"
pngme decode ./dice.png ruSt
pngme remove ./dice.png ruSt
pngme print ./dice.png
应该有四个子命令,每个子命令都有自己的一组参数
Encode 在特定块中藏信息 需要4个参数
- 文件路径
- 块类型
- 想藏的信息
- 输出路径(可选,不写就是覆盖原文件)
Decode 从特定块中解密
- 文件路径
- 块类型
Remove 删掉一个块中藏的信息
- 文件路径
- 块类型
Print 打印所有能藏信息的块类型
- 文件路径
在纠结clap的用法之前,我们得先定义这些命令在Rust的表示,用enum就很不错:
use std::path::PathBuf;
pub enum PngMeArgs {
Encode(EncodeArgs),
Decode(DecodeArgs),
Remove(RemoveArgs),
Print(PrintArgs),
}
pub struct EncodeArgs {
file_path: PathBuf,
chunk_type: String,
message: String,
output: Option<PathBuf>,
}
pub struct DecodeArgs {
file_path: PathBuf,
chunk_type: String,
}
pub struct RemoveArgs {
file_path: PathBuf,
chunk_type: String,
}
pub struct PrintArgs {
file_path: PathBuf,
}
PathBuf是表示文件路径的结构,chatGPT给出了一些解释:
PathBuf和Path是Rust标准库中用于处理文件路径的两个类型。它们的主要区别在于可变性和所有权。
Path类型代表一个不可变的文件路径,而PathBuf类型代表一个可变的文件路径。Path类型的方法返回的是引用类型,不允许修改路径;而PathBuf类型的方法返回的是可变引用类型,允许修改路径。这意味着如果你需要修改一个文件路径,你需要使用PathBuf类型。
clap虽然强大,但是比较复杂,想要整明白还不容易.不过我们这里的需求算是简单,所以还能应付,要是再复杂点可能得借助gpt4了(
clap一般有2种使用方法: build和derive. build比较易懂,但是写起来比较繁琐;derive比较简洁,但是比较难懂
我们这里使用了derive方法,现在arg.rs的内容如下,你可以看到clap的强大之处:
use clap::{Args, Parser, Subcommand};
use std::path::PathBuf;
#[derive(Debug, Parser)]
#[clap(name = "pngme")]
pub struct Cli {
#[clap(subcommand)]
pub subcommand: PngMeArgs,
}
#[derive(Debug, Subcommand)]
pub enum PngMeArgs {
//这个enum的变体就会解析成子命令(不分大小写)
//因为这个enum有Encode/Decode/Remove/Print 4个变体
//所以命令行中就可以输入如 pngme encode ... 这些子命令了
Encode(EncodeArgs),
Decode(DecodeArgs),
Remove(RemoveArgs),
Print(PrintArgs),
}
#[derive(Debug, Args)]
pub struct EncodeArgs {
//通过derive Args 子命令下的参数就会按照这个结构来解析
file_path: PathBuf,
chunk_type: String,
message: String,
output: Option<PathBuf>,
}
#[derive(Debug, Args)]
pub struct DecodeArgs {
file_path: PathBuf,
chunk_type: String,
}
#[derive(Debug, Args)]
pub struct RemoveArgs {
file_path: PathBuf,
chunk_type: String,
}
#[derive(Debug, Args)]
pub struct PrintArgs {
file_path: PathBuf,
}
泰裤辣!(
然后main.rs改成这样:
use clap::Parser;
mod args;
mod chunk;
mod chunk_type;
mod commands;
mod png;
pub type Error = Box<dyn std::error::Error>;
pub type Result<T> = std::result::Result<T, Error>;
fn main() -> Result<()> {
let args = args::Cli::parse();
println!("{:?}", args);
match args.subcommand {
args::PngMeArgs::Encode(encode_args) => commands::encode(encode_args),
args::PngMeArgs::Decode(decode_args) => commands::decode(decode_args),
args::PngMeArgs::Remove(remove_args) => commands::remove(remove_args),
args::PngMeArgs::Print(print_args) => commands::print(print_args),
}
}
commands是我们等下要实现的方法,如果想看看解析的结果,可以先把match那段注释掉
我们来看看疗效
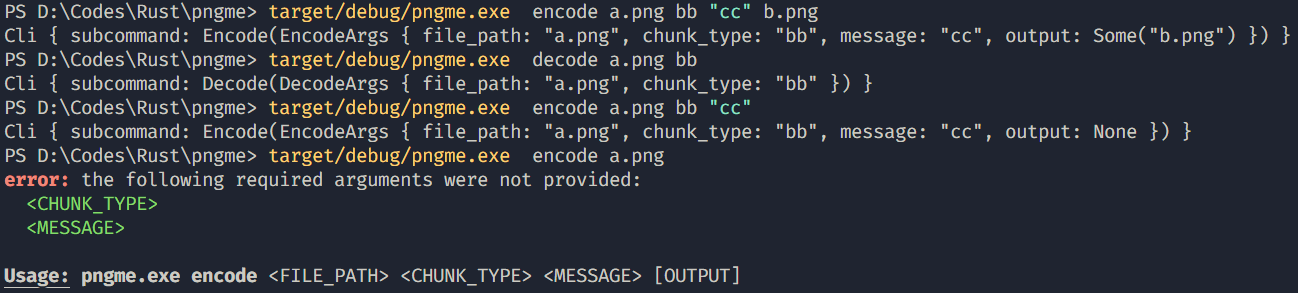
最后 利用之前实现的方法来写command.rs
use crate::args::*;
use crate::chunk::Chunk;
use crate::chunk_type::ChunkType;
use crate::png::Png;
use crate::Result;
use std::fs;
use std::str::FromStr;
pub fn encode(args: EncodeArgs) -> Result<()> {
// check if file exists
if !args.file_path.exists() {
return Err("File does not exist".into());
}
let bytes = fs::read(args.file_path.clone())?;
let mut png = Png::try_from(&bytes[..])?;
let new_chunk = Chunk::new(
ChunkType::from_str(&args.chunk_type)?,
args.message.as_bytes().to_vec(),
);
png.append_chunk(new_chunk);
// write to file
if let Some(output) = args.output {
fs::write(output, png.as_bytes())?;
} else {
fs::write(args.file_path, png.as_bytes())?;
}
Ok(())
}
pub fn decode(args: DecodeArgs) -> Result<()> {
// check if file exists
if !args.file_path.exists() {
return Err("File does not exist".into());
}
let bytes = fs::read(args.file_path)?;
let png = Png::try_from(&bytes[..])?;
// find chunk
let chunk = png
.chunks()
.iter()
.find(|chunk| chunk.chunk_type().to_string() == args.chunk_type)
.ok_or("Chunk not found")?;
// decode message
let message: String = chunk.data().iter().map(|x| *x as char).collect();
println!("{}", message);
Ok(())
}
pub fn remove(args: RemoveArgs) -> Result<()> {
// check if file exists
if !args.file_path.exists() {
return Err("File does not exist".into());
}
let bytes = fs::read(args.file_path.clone())?;
let mut png = Png::try_from(&bytes[..])?;
// remove the chunk
png.remove_chunk(&args.chunk_type)?;
// write to file
fs::write(args.file_path, png.as_bytes())?;
Ok(())
}
pub fn print(args: PrintArgs) -> Result<()> {
// check if file exists
if !args.file_path.exists() {
return Err("File does not exist".into());
}
let bytes = fs::read(args.file_path)?;
let png = Png::try_from(&bytes[..])?;
// print chunks
for chunk in png.chunks() {
println!("{}", chunk);
}
Ok(())
}
我还是加了个chunk_type的to_string方法,主要不想用format!了(
最终成品展示
我们使用维基的骰子图片dice.png作为演示
下面是运行的print的输出:
PS D:\Codes\Rust\pngme\target\debug> .\pngme.exe print .\dice.png
Cli { subcommand: Print(PrintArgs { file_path: ".\\dice.png" }) }
Chunk
Length: 13
Type: IHDR
Data: Invalid UTF-8
CRC: 1807389920
Chunk
Length: 4
Type: gAMA
Data: Invalid UTF-8
CRC: 201089285
Chunk
Length: 46
Type: tEXt
Data: SoftwareXV version 3.10a-jumboFix of 20050410
CRC: 1223306120
Chunk
Length: 8192
Type: IDAT
Data: Invalid UTF-8
CRC: 1808155945
Chunk
Length: 8192
Type: IDAT
Data: Invalid UTF-8
CRC: 977458620
Chunk
Length: 4833
Type: IDAT
Data: Invalid UTF-8
CRC: 4100335391
Chunk
Length: 7
Type: tIME
Data: Invalid UTF-8
CRC: 3731693981
Chunk
Length: 0
Type: IEND
Data:
CRC: 2923585666
我们要encode,不能修改现有chunk的data,不然图片就没法显示了,所以encode是往Vec最后那里加的
PS D:\Codes\Rust\pngme\target\debug> .\pngme.exe encode .\dice.png RuSt "Secret message!" output.png
Cli { subcommand: Encode(EncodeArgs { file_path: ".\\dice.png", chunk_type: "RuSt", message: "Secret message!", output: Some("output.png") }) }
PS D:\Codes\Rust\pngme\target\debug> .\pngme.exe print .\output.png
Cli { subcommand: Print(PrintArgs { file_path: ".\\output.png" }) }
Chunk
Length: 13
Type: IHDR
Data: Invalid UTF-8
CRC: 1807389920
Chunk
Length: 4
Type: gAMA
Data: Invalid UTF-8
CRC: 201089285
Chunk
Length: 46
Type: tEXt
Data: SoftwareXV version 3.10a-jumboFix of 20050410
CRC: 1223306120
Chunk
Length: 8192
Type: IDAT
Data: Invalid UTF-8
CRC: 1808155945
Chunk
Length: 8192
Type: IDAT
Data: Invalid UTF-8
CRC: 977458620
Chunk
Length: 4833
Type: IDAT
Data: Invalid UTF-8
CRC: 4100335391
Chunk
Length: 7
Type: tIME
Data: Invalid UTF-8
CRC: 3731693981
Chunk
Length: 0
Type: IEND
Data:
CRC: 2923585666
Chunk
Length: 15
Type: RuSt
Data: Secret message!
CRC: 1157177192
PS D:\Codes\Rust\pngme\target\debug> .\pngme.exe decode .\output.png RuSt
Cli { subcommand: Decode(DecodeArgs { file_path: ".\\output.png", chunk_type: "RuSt" }) }
Secret message!
可以看到encode和decode的效果
最后来remove我们添加的块:
PS D:\Codes\Rust\pngme\target\debug> .\pngme.exe remove .\output.png RuSt
Cli { subcommand: Remove(RemoveArgs { file_path: ".\\output.png", chunk_type: "RuSt" }) }
PS D:\Codes\Rust\pngme\target\debug> .\pngme.exe print .\output.png
Cli { subcommand: Print(PrintArgs { file_path: ".\\output.png" }) }
Chunk
Length: 13
Type: IHDR
Data: Invalid UTF-8
CRC: 1807389920
Chunk
Length: 4
Type: gAMA
Data: Invalid UTF-8
CRC: 201089285
Chunk
Length: 46
Type: tEXt
Data: SoftwareXV version 3.10a-jumboFix of 20050410
CRC: 1223306120
Chunk
Length: 8192
Type: IDAT
Data: Invalid UTF-8
CRC: 1808155945
Chunk
Length: 8192
Type: IDAT
Data: Invalid UTF-8
CRC: 977458620
Chunk
Length: 4833
Type: IDAT
Data: Invalid UTF-8
CRC: 4100335391
Chunk
Length: 7
Type: tIME
Data: Invalid UTF-8
CRC: 3731693981
Chunk
Length: 0
Type: IEND
Data:
CRC: 2923585666
完美!