试过用Rust写,但是不知道为什么总是403forbidden
我之前是不会写爬虫的,但是因为自己用仓鼠癖,也即是把东西都囤到本地,然后因为之前有某站突然倒掉的事件(虽然之后又重开了),所以看到喜欢的漫画我都会想办法下载下来,就自己搜教程写出了一个爬虫脚本
注意: 由于该漫画网站是外网网站,且爬取图片会损害其利益,故本文章不会涉及该网站实际网址,脚本也不会放github上
首先看看这个漫画网站的结构:
- 具体某个漫画的url: https://xxx.com/漫画id/ 比如某漫画的id是2333,那么对应url就是 https://xxx.com/2333/
- 漫画可以分为多话,url: https://xxx.com/漫画id/话数 但是第一话不用指明话数
- 漫画的标题,作者等信息仅在第一话中展示,这些信息可以在url对应的html代码中找到
- 图片的url: https://yyy.com/漫画对应的固定信息/漫画id/话数/图片编号.jpg 可以在html代码中找到
根据以上信息,脚本大致就要做一下工作:
- 打开url,获取网页的html代码
- 根据漫画第一话的html,获得标题,作者,话数等信息.因为有比较固定的格式,可以使用正则表达式去获取
- 根据各话的html获得所有图片url,也可以使用正则表达式去获取
- 根据漫画的信息显示下载进度
那就开始吧
各模块介绍
一些准备
我们需要一些包和一些准备来支持上述工作,下面给出代码,python版本为3.11
import os # 用于创建文件/目录/代理等
import re # 导入正则表达式模块
import urllib.request # 导入用于打开URL的扩展库模块
import urllib.error # 导入错误,用于try catch
import opencc # 把繁体转为简体,因为网站是繁体中文
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"
t2s = opencc.OpenCC("t2s.json")
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
因为是外网网站,这里使用os.environ指定代理,我用的是clash,默认端口是7890
第10行的t2s使用后续繁体转简体
第12行的headers用于打开url所使用的UA,如果没有UA,一些网站会拒绝python访问
urllib也可以用requests库代替,网上有其他教程,我觉得前者用起来简单一些
打开URL
def open_url(url: str) -> str:
req = urllib.request.Request(
url,
headers=headers,
) # 将Request类实例化并传入url为初始值,然后赋值给req 添加header,伪装成浏览器
# 访问url,并将页面的二进制数据赋值给page
page = urllib.request.urlopen(req)
# 将page中的内容转换为utf-8编码
html = page.read().decode("utf-8")
return html
简单直接,不解释
解析第一话获得漫画信息
def get_info(first_html: str) -> tuple[str, str, str, bool]:
pattern = r'<meta name="keywords" content="(.+)">'
result = re.search(pattern, first_html)
assert result is not None
result = result[1].split(",")
vip_pattern = r'rel="tag">會員專區'
vip_result = re.search(vip_pattern, first_html)
is_vip = vip_result is not None
title = t2s.convert(result[0])
author = result[1]
other_name_p = r"其他名稱:(.+)?</p>"
other_name_result = re.search(other_name_p, first_html)
other_name = other_name_result[1] if other_name_result is not None else ""
return title, author, other_name, is_vip
输入漫画第一话html代码,返回漫画的标题,作者,别名,是否为vip专享
为什么是第一话? 因为只有第一话的html才有这些信息,其他话就没有了
各种pattern是正则表达式匹配html中的内容,比如第2行,假如漫画标题是aaa,作者是bbb,那么html的内容就会是<meta name="keywords" content="aaa,bbb">.我们用正则匹配出aaa,bbb之后就可以split出来了
因为漫画大都是日/韩漫,所以有日/韩文名,这时候别名就是它的日/韩文名,而标题一般是该漫画的中文名,但也有可能没有别名
is_vip表明了该漫画是否为vip专享,如果是vip专享,我们只能看到漫画的一些内容,之后的就看不到了(虽然也不是完全没办法,但我不会特地公开)
解析其他话的URL
def get_rest_url(html) -> list[str]:
# 取得剩下集数的html,这个pattern不会搜索到当前的html
pattern = r'<a href="(.+?)" class="post-page-numbers"'
result = re.findall(pattern, html)
return result
假如该漫画有5话,我们把第一话的html丢给该函数,就会返回2,3,4,5话的url,而不包含1话
解析URL是哪一话
def get_episode(url: str) -> tuple[str, int]:
pattern = r"https://xxx.com/([0-9]+)/([0-9]+)"
result = re.search(pattern, url)
if result is None:
return url, 1
episode = int(result[2])
main_url = f"https://xxx.com/{result[1]}"
return main_url, episode
输入漫画任意一话的url,返回该漫画的主url(也就是第一话)和当前话数
为什么会有这个需求? 因为我们并不总是想要从第1话开始下载,如果该漫画现在共有5话,但是没有完结,你下载了5话.之后漫画又更新了2话,那你就应该从5话开始下载,这时候传入第5话的url,就知道你想从第5话开始下载,同时获得第1话的url(因为需要漫画的信息)
下载图片并保存
req = urllib.request.Request(img_url, headers=headers)
img = urllib.request.urlopen(req)
with open(path, "wb") as f:
f.write(img.read())
这里没有把它们整合成函数,是因为实作中1-2行和3-4行因某些原因需要分开,后面会解释
总体代码
if __name__ == "__main__":
while True:
url = input("输入网址: ").strip()
try:
comic = Comic(url)
except Exception as e:
print(e)
else:
comic.download()
print("下载完成!\n")
我们循坏获取url的输入,并创建一个Comic类,然后调用download方法. 这里用try catch让一些小错误不至于直接崩溃并打印出错误.比如输错url
Comic类
我们一段一段来看
class Comic:
def __init__(self, url: str):
self.episode_list: list[Episode] = [] # 存放每话的url
self.first_html = open_url(url) #传入url的html,不一定总是第1话的url
rest_html = [open_url(x) for x in get_rest_url(self.first_html)]
self.total_episode = len(rest_html) + 1 # rest_html少了first_html自身的一话
self.main_url, self.first_episode = get_episode(url)
self.episode_html_list = [self.first_html] + rest_html[self.first_episode - 1 :]
最后一行有一点绕,我们从头到尾来看下:
假设该漫画现在共有7话,我们想要第5话开始下载
那我们就传入第5话的url来创建Comic类.self.first_html就是第5话的html,rest_html是除第5话外其他话的url,也就是1,2,3,4,6,7话(其他话的url不用一定在第1话的html获取,其他话也有,不然实际浏览时怎么跳转?).self.total_episode就是6+1=7话,然后self.main_url, self.first_episode就是第一话的url和当前url的话数(5). 我们需要第一话的url来提供漫画信息和拼接其他话数的url(https://xxx.com/漫画id/话数 但是第一话不用指明话数,所以话数为空,利于拼接).最后self.episode_html_list就是self.first_html加上rest_html从第五话开始之后的所有话数,也就是**[5]**+[1,2,3,4,6,7]中加粗部分
之后是一些os的工作和信息打印
self.title, self.author, self.other_name, self.is_vip = get_info(
open_url(self.main_url)
)
dir_name = f"[{self.author}]{self.title}"
if self.other_name != "":
dir_name += f"|{self.other_name}"
# win的目录不能包含一些符号
dir_name = re.sub(r"[\/\\\:\*\?\"\<\>\|]", " ", dir_name)
self.dir_path = f"D:/zzz/{dir_name}"
if not os.path.exists(self.dir_path):
os.mkdir(self.dir_path)
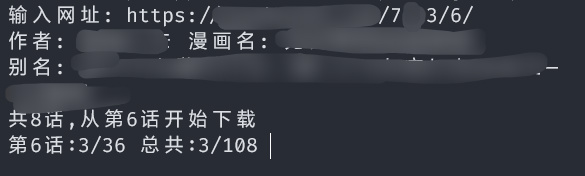
print(f"作者: {self.author} 漫画名: {self.title}")
if self.other_name != []:
print(f"别名: {self.other_name}")
if self.is_vip:
print("vip漫画")
print(f"共{self.total_episode}话,从第{self.first_episode}话开始下载")
应该挺好懂的,不多解释了
最后对各个话创建Episode类,在该类里单独处理一话的内容
self.total_img = 0
for i, url in enumerate(self.episode_html_list, self.first_episode):
episode = Episode(url, i, self.dir_path)
self.episode_list.append(episode)
self.total_img += len(episode)
Episode类需要该话的url,该话的话数,下载目录.
self.total_img是图片总数,用于后续打印信息
Comic类的download方法
def download(self):
already_downloaded = 0
for e in self.episode_list:
e.download(already_downloaded, self.total_img)
already_downloaded += len(e)
只是记录已经下载了多少图片,具体下载要给到Episode类,Episode类也有一个download方法
Episode类
Episode类也挺长,也一段一段看
class Episode:
def __init__(self, html: str, episode: int, dir_path: str):
self.html = html
self.episode = episode
self.is_vip = is_vip_chapter(self.html)
self.dir_path = dir_path
self.set_img_list()
def __len__(self):
return len(self.img_list)
def set_img_list(self):
p = r'data-src="(https://yyy/.*?.jpg)"'
self.img_list = re.findall(p, self.html)
if self.is_vip:
pass
self.is_vip用于表示本话是不是vip话,前面说过有些漫画是vip话,但该漫画不是所有话都没法看,有些还是能免费看的,所以需要分别处理
set_img_list用于获取该话全部图片的url,然后根据该话是否为vip话进行处理(该文章不会涉及)
下载部分
def download(self, already_downloaded: int, total_img: int):
for i, img_url in enumerate(self.img_list, 1):
self.try_download_img(img_url)
print(
"\033[K"
+ "\r"
+ f"第{self.episode}话:{i}/{len(self)} 总共:{already_downloaded+i}/{total_img} ",
end="",
flush=True,
)
def try_download_img(self, img_url: str) -> bool:
img_fullname = f'{self.episode}_{img_url.split("/")[-1]}'
path = f"{self.dir_path}/{img_fullname}"
if os.path.exists(path):
return True
try_time = 0
while True:
try:
req = urllib.request.Request(img_url, headers=headers)
img = urllib.request.urlopen(req)
except urllib.error.URLError as e:
try_time += 1
if try_time >= 5:
print(f"{e} at {img_url}")
raise e
else:
save_photo(img, path)
return True
这里我感觉挺屎山的,但是能用(
download基本是打印信息用的,print中的"\033[K""\r"用于把光标退到改行的开头,flush=True允许覆盖当前行的内容
try_download_img输入图片的url,返回图片下载是否成功.但其实download里并没有使用到这个bool值,其实这个bool值在其他地方有用,但是这里不会涉及(
因为我们是用代理下载图片的,有可能会抽风,这里except urllib.error.URLError as e:就是用来重试url错误的,以免抽风一次就直接不干了
自此,整个脚本就完成了
脚本运行的截图: